



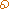
In this post we want to offer a look behind the scenes at the work involved in the Provenance Index through a case study of the recent German Sales Catalogs project, which added over a quarter million records for art objects looted and sold under the cultural policy of the Nazi regime. The project brought together auction catalogs from 35 German, Swiss, and Austrian institutions, with most drawn from the collections of the GRI’s project partners, the Kunstbibliothek (Art Library) of the State Museums in Berlin and University Library at Heidelberg, and made them fully searchable online.
Incorporating this data into the Provenance Index and making it searchable and error-free took our small staff of art historians and information systems specialists about two years. Here’s how we did the work.
Step 1: Scanning and Performing OCR
Our colleagues at Heidelberg performed the massive feat of digitizing almost 200,000 pages of auction catalogs and making them available online, both as PDFs and as searchable text generated via OCR (optical character recognition). Because they did not clean up any of the OCR-generated text, searching errors can severely hinder a researcher’s work.
To show what we mean, here’s an example of “edited” data from a single page of a 1937 sales catalog. The generated text matches the original exactly.

A “clean” scan: portion of a scanned PDF of a 1937 auction catalog with its OCR-generated text (inset) The text matches the original exactly.
By contrast, the example below contains several errors. For example, “Sechsteilige” (six-part) is misspelled as “Sechsteiuge,” the numbering for lots 421–426 is missing entirely, and catalog entry 429 is misread as item 420.

A “dirty” scan: portion of a scanned PDF of a 1937 auction catalog with its OCR-generated text (inset). Red arrows point to errors.
Step 2: Parsing the Data via Computer Program
The most difficult—and actually the most unusual—part of the entire project was figuring out how to parse the OCR text. Rather than transcribing and parsing it all by hand (which would have been impossible given the volume of information and the time constraints of the project), we developed custom software to do the job. These programs analyzed the structure of each block of OCR text, determined what data elements were present and where they began and ended, then parsed these out and placed them into Excel spreadsheets for review and further enhancement by editors at the Getty Research Institute’s Project for the Study of Collecting and Provenance (PSCP). From 2011 to the end of 2012, three staff members processed 1,600 auction catalogs this way: Suzanne Michels, programming consultant for the Research Institute’s Information Systems Department, who created the parsing code, and two part-time research assistants in the PSCP.
When we began in 2011, we had no firm requirements, only a handful of catalogs, and no idea yet about the wide variety of formats we would eventually encounter. So we started by creating a semi-automated system to download scanned catalogs from Heidelberg and to avoid repeat downloads of previously received catalogs. This system used UNIX shell scripting and the Perl programming language. Ultimately, we chose Perl for parsing because it’s a flexible language that allows for modularized, easily extensible code, and particularly for its superior text-processing ability.
We developed an initial processing algorithm (in lay speak: program for parsing the data) based on the first format we had in hand, a 1937 catalog from the Lepke Auction House. We used this algorithm throughout the project, adjusting it as we went by adding preprocessors (explained below).
The auction catalogs have two basic formats that our scripts had to accommodate. The first format, illustrated below, lists the artist’s name in all caps, followed occasionally by additional artist info, such as location and life dates, and a description of the artwork.

Portion of a scanned page from a 1937 German sales catalog. In this catalog, the artist’s name comes first in all caps, followed by additional info.
The second format shows a description of the artwork only (here, beginning in all caps), with no artist’s name or maker description.

Portion of a scanned page from a different German sales catalog. In this catalog, the artwork’s description is in all caps, followed by a description of the work; no maker name is listed.
The data varied widely, but our program didn’t “know” that. It quite naturally expected unvarying formatting from catalog to catalog and record to record. Rewriting the program to suit each newly encountered format would have been slow, unwieldy, and inefficient. Instead, we created preprocessing scripts to transform the data’s format before feeding it to the main program. Ultimately, we created several dozen of these preprocessors to handle often subtle differences between formats. The challenge became selecting the correct preprocessor for the data. Sometimes we needed to run multiple preprocessors: one to normalize the numbering and spacing of data, for example, followed by a second to apply additional reformatting.
One challenge was numbers. The numbering of auction lots varied from catalog to catalog, and sometimes within sections of a single catalog. Numbers were combined with letters (31a, 31b, etc.), appeared as ranges (129–134, 247–248, etc.), or had unexpected separators such as slashes (12/13, 192/195, etc.). We continually enhanced our code to recognize and accommodate these variations.
Another challenge was proper names. In some catalogs, there was no way to distinguish text that might be an artist’s name from other text without comparing it to known artists’ names. So we created a Microsoft Access database of artists’ names, populating and continually updating it as the catalogs were processed. Somewhat paradoxically, we found it necessary to add misspelled names to the database since the OCR repeatedly misread names. Later, in the editing process, we would correct these misspellings.
Handling the large volume of data was a project-management challenge. We developed a detailed tracking system for processing, editing, and loading data in order to stay on top of the weekly influx of catalogs. We prioritized catalogs for processing that listed solely paintings, drawings, and sculptures, as opposed to other items that frequently appear, such as books, coins, and household goods. As a result, nearly a quarter of the approximately 2,800 catalogs that Heidelberg scanned were outside the scope of our project. Our goal at this stage was to prepare spreadsheets for the relevant catalogs that could be easily reviewed and enhanced by editors, and that contained as much data as possible, including dimensions, media type, materials, category, etc., extracted automatically.
Here’s an example of a PDF scan of a 1937 catalog and the corresponding spreadsheet that resulted from parsing the data. It’s important to note that by automatically including the page number on which a lot appeared in the scanned catalog, we were able to provide direct links from the Provenance Index records to the exact location within a PDF.

Sample PDF scan of a German sales catalog with a screen capture of the corresponding spreadsheet that resulted from parsing the data.
Step 3: Proofing, Correcting, and Enhancing the Data by Hand
Once the computer processing was complete, editors in the PSCP began the meticulous process of hand-editing these spreadsheets in Excel. They spell-checked, marked lots to be made available on the web, and performed lot-by-lot reviews against the PDFs for omissions and other errors.
Beyond correcting, they also enhanced the catalog data by adding classifications (such as genre and subject), transcribing handwritten annotations from the catalog margins, and incorporating published sale prices from primary sources such as the periodicals Internationale Sammler-Zeitung and Weltkunst. Significant effort was also made to validate artist names against the Provenance Index’s own authority database of names and to add artists’ nationalities.
Altogether, two staff editors, Anna Cera Sones and Lin Barton, one consultant editor in Berlin and one in Vienna, and various research assistants and graduate interns processed over 980,000 records and designated over 236,000 records for paintings, sculptures, and drawings to be made available on the web.
Step 4: Developing the Databases
While the catalogs were being scanned, processed, and edited, Ruth Cuadra, an application systems analyst in the Research Institute’s Information Systems Department, was working to adapt database designs for existing Provenance Index databases to accommodate the new German Sales catalog data. New databases were needed both for the content of the catalogs and for the bibliographic descriptions of the catalogs themselves. A key feature of the Provenance Index is that researchers can link back and forth between the artworks detailed in the catalogs and reference information about the catalogs themselves.
Her work for the catalog content database included adding new fields, including genre, subject, object type, estimated price, starting price, a link to the relevant PDF on the Heidelberg library website, and the page number for each lot within the PDF. She also converted all standardized text for attribution modifiers, transaction types, genre, subject, object type, and format into German using translations provided by editors at the PSCP.
To manage the constant flow of catalogs as efficiently as possible, Ruth created an automated process for converting edited spreadsheets to tab-delimited format and ingesting them into our database system, STAR, and performing global changes and data cleanups.
To build the catalog descriptions database, she converted a database created using Microsoft Access by the Kunstbibliothek to STAR, the system we use for the Provenance Index. This database, which includes locations of hand-annotated copies of catalogs that may not have been considered for digitization, was edited and enhanced with the addition of links to the catalog PDFs at the University of Heidelberg. In all, more than 2,850 descriptions of German auction catalogs are now available in the Provenance Index to assist researchers in understanding the information provided in the records of the individual lots.
The sequence of screenshots below shows how a researcher can access not only information on individual objects, but also the catalogs from which they were scanned.
On the initial query screen, the researcher enters search criteria. This leads to multiple individual object records, an example of which (for the sculpture of Saint John the Baptist now owned by the Getty Museum) is shown in the second image below.

Initial query screen of the Sales Catalogs database within the Getty Provenance Index, showing search criteria entered for the wood sculpture of St. John the Baptist (Johannes der Täufer).

Sample result within the Sales Catalog database for the sculpture of Saint John the Baptist now owned by the Getty Museum.
On this object record, the “Sale Description” link takes the researcher to bibliographic information about the catalog itself.
This Sale Description record has another link, “Sale Contents,” that takes the researcher to records of other artworks sold in the same auction. The link for “Catalog PDF,” meanwhile, provides direct access to the scanned original. As an aid to the researcher, each catalog link goes directly to the page of the corresponding PDF on which the particular auction lot appears.
Step 5: Publishing the Data Online
The final step was to make all of this edited and newly enhanced data publicly searchable as part of the Getty Provenance Index. All told, it now features about 236,000 art-sale records from more than 1,600 German auction catalogs dating from 1930 to 1945, all within a rich context as shown above.
The result of two years of work, this new information will not only promote a fuller understanding of Nazi cultural policy, but will enable scholars to better understand the dynamics of art markets in the 20th century. It also, we hope, will allow greater interdisciplinary exchange among scholars from a variety of fields, including art history, economics, and cultural studies.

2 Comments
This is amazing! After having OCR’d countless german and dutch texts, I appreciate this so much. Will the software for recognizing and parsing out the sections be made open source at some point? I have noticed that Acrobat’s OCR technology is not as good as whatever Google Books uses, and that it has trouble with Serif scripts, mixing up the t’s and r’s, and the e’s and c’s.
Hi Jun,
We have actually never discussed open sourcing the parsing code, but there is really no reason why we couldn’t. That said……the code is highly specific to the texts we are parsing so it is one of these “your mileage may vary” situation for being able to use the code effectively out of the box.
I’ll talk with my development team about how we might package and document the code base to make it distributable.
Best regards,
Joe Shubitowski
Head, Information Systems
Getty Research Institute
Source:
Getty Iris accessed 22 April 2013
http://blogs.getty.edu/iris/publishing-german-sales-a-look-under-the-hood-of-the-getty-provenance-index/